流量统计架构
类关系图
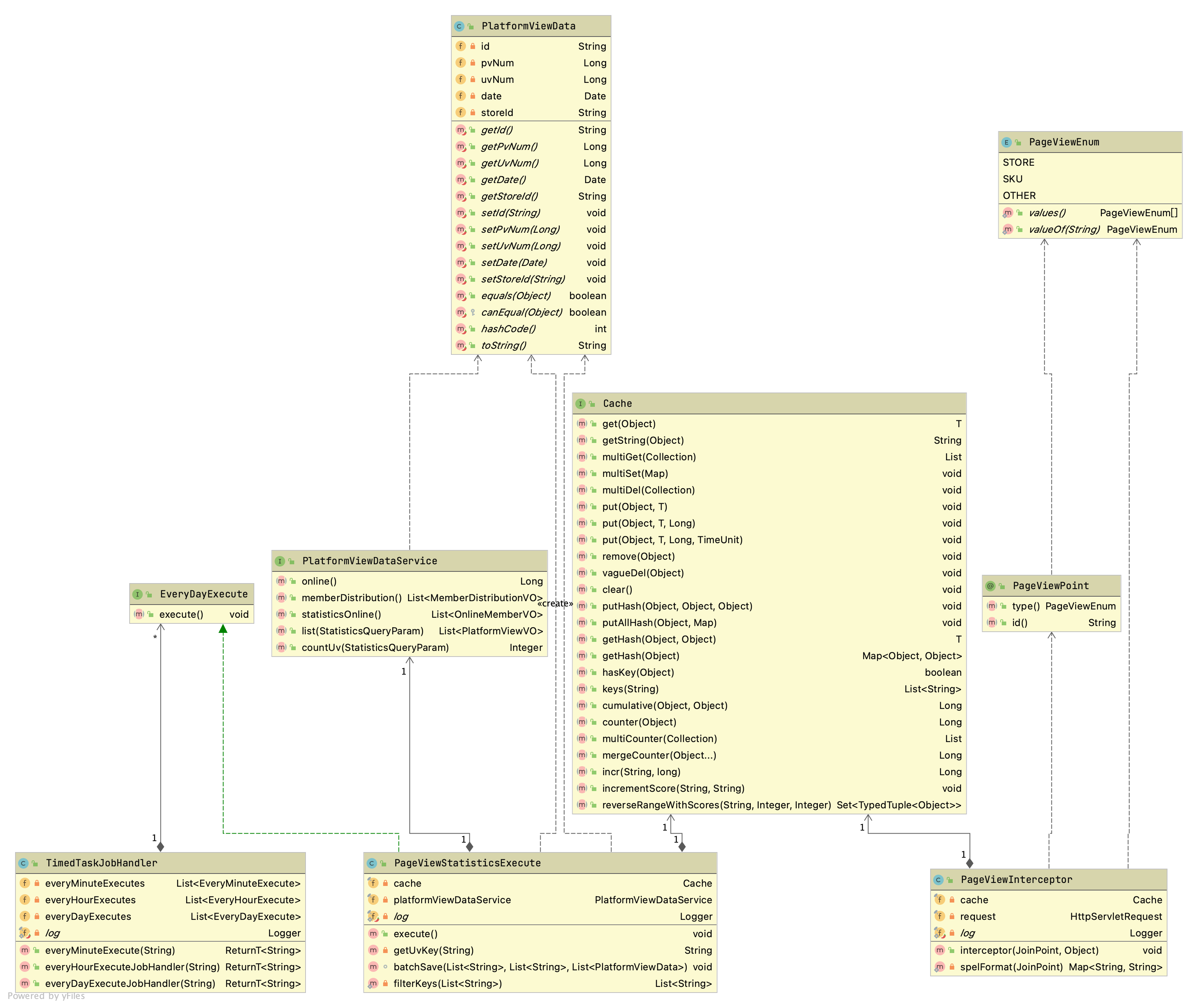
说明
PageViewEnum 流量统计枚举,统计商品sku流量、店铺流量、其他流量
PageViewPoint 流量统计切点,注入到业务代码中,如商品服务中
// 获取商品详情API @ApiOperation(value = "通过id获取商品信息") @ApiImplicitParams({ @ApiImplicitParam(name = "goodsId", value = "商品ID", required = true, paramType = "path"), @ApiImplicitParam(name = "skuId", value = "skuId", required = true, paramType = "path"), @ApiImplicitParam(name = "distributionId", value = "分销商ID", dataType = "String", paramType = "query") }) @GetMapping(value = "/sku/{goodsId}/{skuId}") @PageViewPoint(type = PageViewEnum.SKU, id = "#id") public ResultMessage<Map<String, Object>> getSku(@NotNull(message = "商品ID不能为空") @PathVariable("goodsId") String goodsId, @NotNull(message = "SKU ID不能为空") @PathVariable("skuId") String skuId, String distributionId) { Map<String, Object> map = goodsSkuService.getGoodsSkuDetail(goodsId, skuId); //判断如果传递分销员则进行记录 if (CharSequenceUtil.isNotEmpty(distributionId)) { distributionService.bindingDistribution(distributionId); } return ResultUtil.data(map); }PageViewInterceptor 流量切入业务,对请求进行处理,记录商品流量/店铺流量
TimedTaskJobHandler xxljob 分布式任务调度中心,负责每日任务调度,进行昨日流量汇总
EveryDayExecute 每日任务接口,流量统计属于每日任务
PageViewStatisticsExecute 流量统计执行,即流量业务汇总具体业务类
Cache 高性能流量记录方法,后续会有具体说明及其示例、含义
PlatformViewData 流量持久化对象,包含店铺id、pv、uv、日期等关键字段
流程图
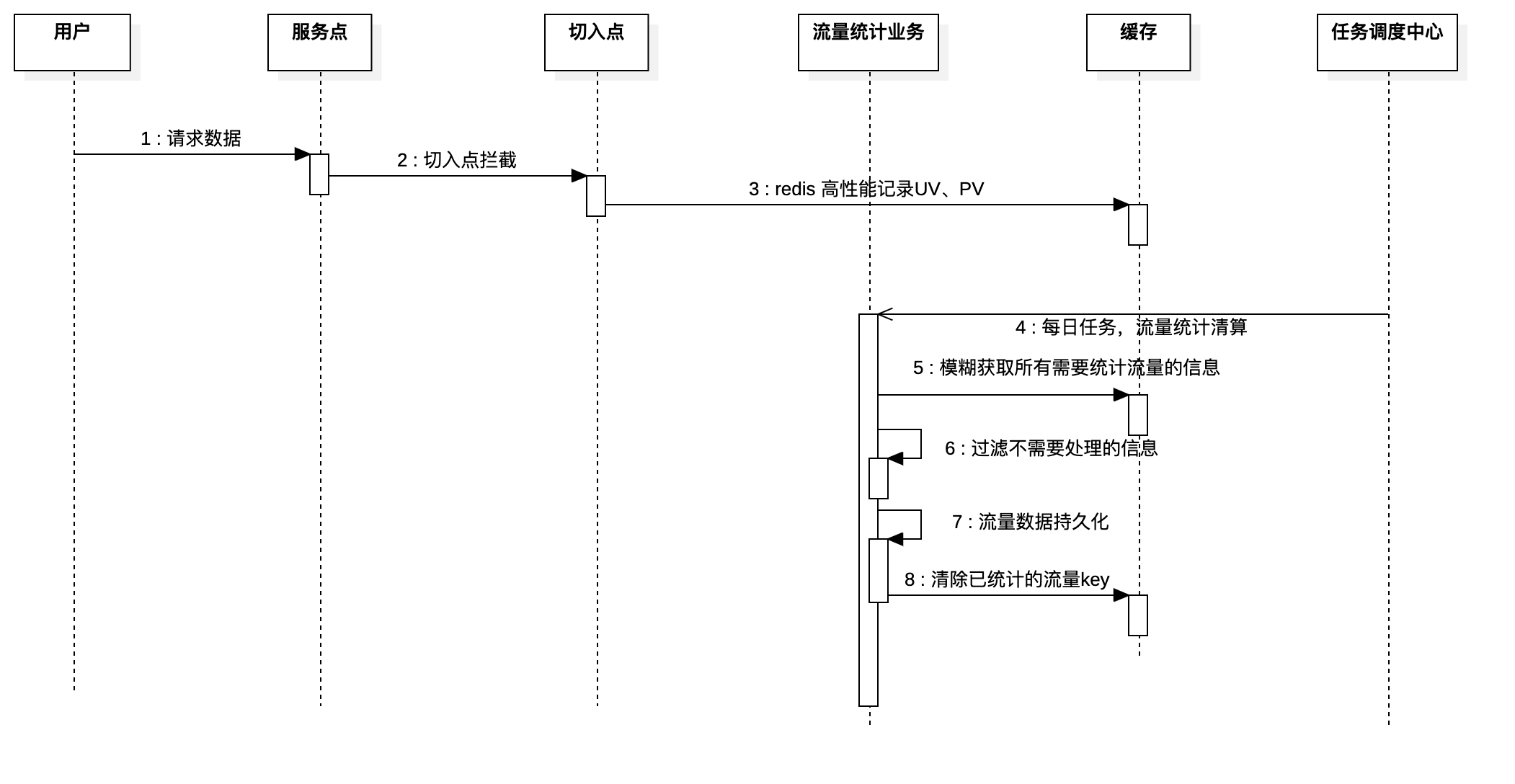
说明
- 用户请求店铺信息、商品信息等需要流量统计的业务
- 切点被aop拦截执行
- redis高性能计数器和高性能去重统计,分别记录PV和UV
- 每日任务调度中心调用流量统计每日任务
- redis中模糊获取待入库的流量信息
- 由于任务是第二天执行,第二天可能还有产生流量数据,所以需要过滤不需要统计的信息
- 数据批量持久化到数据库
- 清除缓存中的流量信息
架构描述
在这块代码中,主要用到了redis的计数器,以及redis的HyperLogLog,这两个工具类用的好,可以大大提升服务器性能,具体优势我已经加入超链接,可以点过去看一下,如果发现文章描述的不清楚,可以去百度,google 或者论坛,看看别人的使用方法以及对该功能的描述。
计数器用于PV统计,HyperLogLog用于UV统计,同时记录店铺UV、PV和平台的UV、PV。目前没有拆分到商品流量统计级别,如果需要这样处理,那么这块代码需要翻一倍,在代码测试中测试,单节点2000次循环,执行时间不到1秒,但是实际应用场景,商品流量的统计准备放在后边继续实现。示例代码中,通过缓存有规律的key来处理流量的累积。
//平台PV 统计48小时过期 留下一定时间予以统计累计数据库 cache.incr(CachePrefix.PV.getPrefix() + StatisticsSuffix.suffix(), 60 * 60 * 48); //平台UV统计 cache.cumulative(CachePrefix.UV.getPrefix() + StatisticsSuffix.suffix(), ip); //店铺PV 统计48小时过期 留下一定时间予以统计累计数据库 cache.incr(CachePrefix.STORE_PV.getPrefix() + StatisticsSuffix.suffix(storeId), 60 * 60 * 48); //店铺UV 统计,则需要对id去重复,所以如下处理 cache.cumulative(CachePrefix.STORE_UV.getPrefix() + StatisticsSuffix.suffix(storeId), ip);流量结果处理,位于每日流量统计的代码的地方。通过模糊匹配key值的规则,得到系统中需要处理的数据,在key的获取中,我们看到一个filterKeys的方法。这个方法主要负责过滤今天的数据,即流量统计数据生成只生成昨天即以前的数据,另外在上一段代码中我们可以看到有效时间是48小时,也就是说,如果服务器连续down机3天,那么流量就会空缺,上一段代码的缓存有效时间可以适当加长。
//1、缓存keys 模糊匹配 //2、过滤今日的数据,即今天只能统计今日以前的数据 // 4对key value 分别代表平台PV、平台UV、店铺PV、店铺UV List<String> pvKeys = filterKeys(cache.keys(CachePrefix.PV.getPrefix() + "*")); List<Integer> pvValues = cache.multiGet(pvKeys); List<String> storePVKeys = filterKeys(cache.keys(CachePrefix.STORE_PV.getPrefix() + "*")); List<Integer> storePvValues = cache.multiGet(storePVKeys);流量结果处理后,批量保存数据库数据成功后,则会删除对应的缓存key,那么下次统计就不会在此统计这一天的数据了。流量统计到此结束。
/** * 批量保存数据&&清除保存数据的缓存 * * @param pvKeys PV key * @param uvKeys UV key * @param platformViewData DOS */ @Transactional(rollbackFor = Exception.class) void batchSave(List<String> pvKeys, List<String> uvKeys, List<PlatformViewData> platformViewData) { log.debug("批量保存流量数据,共计【{}】条", platformViewData.size()); platformViewDataService.saveBatch(platformViewData); //批量删除缓存key cache.multiDel(pvKeys); cache.multiDel(uvKeys); log.debug("流量数据保存完成"); }